This posting is a direct update on this posting. For self-containment, I preserve a lot of the text from that posting, with additional text on the updates where necessary. The list of updates is as follows:
The three tables below should contain all the information necessary for any forecasting machinery to be able to arrive at a corresponding \(\sigma_r\). The cyan colored boxes represent the \(0^{th}\) order information for a first-pass forecast. In addition, for a more detailed approach, full bandpower window functions, bandpasses, and \(N_l\)'s have also been provided.
| \(\nu\),GHz | \(\Delta \nu/\nu\) | FWHM, arcmin | Bandpass, [\(\nu\),\(B_{\nu}\)] | BPWF |
|---|---|---|---|---|
| 30 | 0.30 | 76.6 | bandpass30.txt | bpwfS4.dat |
| 40 | 0.30 | 57.5 | bandpass40.txt | ↑ |
| 85 | 0.24 | 27.0 | bandpass85.txt | | |
| 95 | 0.24 | 24.2 | bandpass95.txt | | |
| 145 | 0.22 | 15.9 | bandpass145.txt | | |
| 155 | 0.22 | 14.8 | bandpass155.txt | | |
| 215 | 0.22 | 10.7 | bandpass215.txt | | |
| 270 | 0.18 | 8.5 | bandpass270.txt | | |
As mentioned in the text above, the effort distributions in the tables below were calculated given an optimized solution for a minimal \(\sigma_r\), taking into account contributions from foregrounds and CMB lensing. The assumed unit of effort is equivalent to 500 det-yrs at 150 GHz. For other channels, the number of detectors is calculated as \(n_{det,150}\times \left(\frac{\nu}{150}\right)^2\), i.e. assuming comparable focal plane area. A conversion between the (150 equivalent) number of det-yrs and (actual) number of det-yrs is given for each band. This is just one way to implement a detector cost-function, and other suggestions are welcomed.
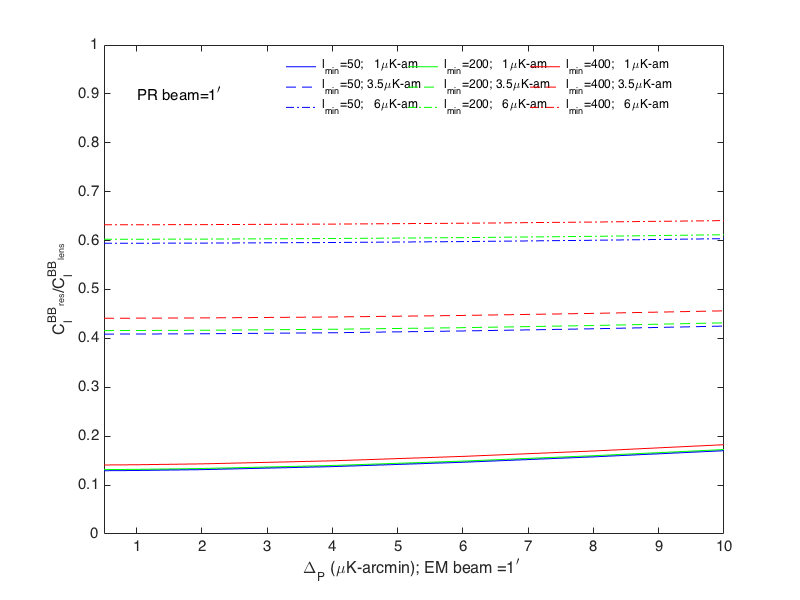
For each case, I list the fraction of effort spent towards solving the foreground separation problem ("degree-scale effort") and reducing the lensing contribution ("arcmin-scale effort"). For the arcminute scale effort, to calculate an effective level of residual lensing, an experiment with \(1\) \(arcmin\) resolution, and mapping speed equivalent to the 145 channel was assumed, hence the conversion between (150 equiv) and (actual); however, all that is necessary to take away (on the delensing front) from these tables are the arcmin-scale map-depths. Then, using an iterative estimator, a \(C_{\ell, res}/C_{\ell, lens}\) is calculated, the results of which are presented in this plot. PR stands for the experiment used for "phi/lensing reconstruction," and EM stands for the experiment (or combination of experiments) used for getting the E-modes. The combined map-depth of EM is assumed to be \(1 \mu K\)-arcmin, though we've seen before (from Kimmy) that the ratio of \(C_{\ell, res}/C_{\ell, lens}\) depends quite little on this noise, as seen here. The \(l_{min}\) in the plot is for the E/B inputs to \(\Phi\); all cases assume complete E-mode coverage (i.e. good coverage for \(l>30\)) for the formation of the B-mode template. Practically, this is a scenario in which the arcmin-scale experiment may be noisy at low \(l\), but we can nonetheless measure all of the E-modes through this range to the level of precision required either with the arcmin-scale or degree-scale experiments. This complete E-mode map is then used to form a B-template by lensing these E-modes with the reconstructed \(\Phi\).
For the various cases, given a fixed effort, the map-depths and \(N_l\)'s are scaled
accordingly with \(f_{sky}\).
| \(f_{sky}=0.01\) | \(f_{sky}=0.05\) | \(f_{sky}=0.10\) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| \(\nu\),GHz | # det-yrs (150 equiv) | # det-yrs (actual) | map depth, \(\mu K\)-arcmin | \(N_l\), \(\mu K_{CMB}^2\) | # det-yrs (150 equiv) | # det-yrs (actual) | map depth, \(\mu K\)-arcmin | \(N_l\), \(\mu K_{CMB}^2\) | # det-yrs (150 equiv) | # det-yrs (actual) | map depth, \(\mu K\)-arcmin | \(N_l\), \(\mu K_{CMB}^2\) |
| 30 | 16,250 | 650 | 5.62 | Nl_r0_fsky1 | 28,750 | 1,150 | 9.46 | Nl_r0_fsky5 | 28,750 | 1,150 | 13.37 | Nl_r0_fsky10 |
| 40 | 16,250 | 1,160 | 5.73 | Nl_dl1_r0_fsky1 | 28,750 | 2,040 | 9.64 | Nl_dl1_r0_fsky5 | 28,750 | 2,040 | 13.63 | Nl_dl1_r0_fsky10 |
| 85 | 127,500 | 40,940 | 0.96 | ↑ | 170,000 | 54,590 | 1.86 | ↑ | 186,250 | 59,810 | 2.52 | ↑ |
| 95 | 127,500 | 51,140 | 0.79 | ↑ | 170,000 | 68,190 | 1.53 | ↑ | 186,250 | 74,710 | 2.06 | ↑ |
| 145 | 87,500 | 81,760 | 0.84 | ↑ | 87,500 | 81,760 | 1.87 | ↑ | 87,500 | 81,760 | 2.65 | ↑ |
| 155 | 87,500 | 93,430 | 0.87 | ↑ | 87,500 | 93,430 | 1.94 | ↑ | 87,500 | 93,430 | 2.74 | ↑ |
| 215 | 55,000 | 112,990 | 2.14 | ↑ | 42,500 | 87,310 | 5.43 | ↑ | 55,000 | 112,990 | 6.76 | ↑ |
| 270 | 55,000 | 178,200 | 3.20 | ↑ | 42,500 | 137,700 | 8.14 | ↑ | 55,000 | 178,200 | 10.11 | ↑ |
| Total Degree Scale Effort | 572,500 | 560,270 | ~ | ~ | 657,500 | 526,180 | ~ | ~ | 715,000 | 604,100 | ~ | ~ |
| Total Arcmin Scale Effort | 427,500 | 399,470 | 0.38 (A_L=0.048) | ~ | 342,500 | 320,050 | 0.94 (A_L=0.121) | ~ | 285,000 | 266,320 | 1.47 (A_L=0.188) | ~ |
| Total Effort | 1,000,000 | 959,740 | ~ | ~ | 1,000,000 | 846,230 | ~ | ~ | 1,000,000 | 870,420 | ~ | ~ |
| \(f_{sky}=0.01\) | \(f_{sky}=0.05\) | \(f_{sky}=0.10\) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| \(\nu\),GHz | # det-yrs (150 equiv) | # det-yrs (actual) | map depth, \(\mu K\)-arcmin | \(N_l\), \(\mu K_{CMB}^2\) | # det-yrs (150 equiv) | # det-yrs (actual) | map depth, \(\mu K\)-arcmin | \(N_l\), \(\mu K_{CMB}^2\) | # det-yrs (150 equiv) | # det-yrs (actual) | map depth, \(\mu K\)-arcmin | \(N_l\), \(\mu K_{CMB}^2\) |
| 30 | 28,750 | 1,150 | 4.23 | Nl_r01_fsky1 | 41,250 | 1,650 | 7.89 | Nl_r01_fsky5 | 41,250 | 1,650 | 11.16 | Nl_r01_fsky10 |
| 40 | 28,750 | 2,040 | 4.31 | Nl_dl1_r01_fsky1 | 41,250 | 2,930 | 8.04 | Nl_dl1_r01_fsky5 | 41,250 | 2,930 | 11.38 | Nl_dl1_r01_fsky10 |
| 85 | 151,250 | 48,570 | 0.88 | ↑ | 195,000 | 62,620 | 1.74 | ↑ | 211,250 | 67,830 | 2.36 | ↑ |
| 95 | 151,250 | 60,670 | 0.72 | ↑ | 195,000 | 78,220 | 1.43 | ↑ | 211,250 | 84,730 | 1.94 | ↑ |
| 145 | 50,000 | 46,720 | 1.11 | ↑ | 50,000 | 46,720 | 2.48 | ↑ | 50,000 | 46,720 | 3.50 | ↑ |
| 155 | 50,000 | 53,390 | 1.45 | ↑ | 50,000 | 53,390 | 2.56 | ↑ | 50,000 | 53,390 | 3.62 | ↑ |
| 215 | 42,500 | 87,310 | 2.43 | ↑ | 42,500 | 87,310 | 5.44 | ↑ | 42,500 | 87,310 | 7.69 | ↑ |
| 270 | 42,500 | 137,700 | 3.64 | ↑ | 42,500 | 137,700 | 8.13 | ↑ | 42,500 | 137,700 | 11.50 | ↑ |
| Total Degree Scale Effort | 545,000 | 437,550 | ~ | ~ | 657,500 | 470,540 | ~ | ~ | 690,000 | 482,280 | ~ | ~ |
| Total Arcmin Scale Effort | 455,000 | 425,170 | 0.37 (A_L=0.047) | ~ | 342,500 | 320,050 | 0.95 (A_L=0.122) | ~ | 310,000 | 289,680 | 1.41 (A_L=0.181) | ~ |
| Total Effort | 1,000,000 | 862,720 | ~ | ~ | 1,000,000 | 790,590 | ~ | ~ | 1,000,000 | 771,960 | ~ | ~ |
In this section, I use fully descriptive BPCM's (more details about the treatment of noise and signal in the formation of the BPCM can be found in Section 1 of this posting) as inputs to the Fisher Forecasting framework (described in Sections 1 and 2 of the same posting linked above). However, the \(N_l\) files above should be compatible with the used BPCM's.
| \(f_{sky}=0.01\) | \(f_{sky}=0.05\) | \(f_{sky}=0.10\) | |
|---|---|---|---|
| \(\sigma_r(r=0, A_L<1), \times 10^{-3}\) | 0.55 | 0.81 | 0.95 |
| \(\sigma_r(r=0, A_L=1), \times 10^{-3}\) | 6.14 | 3.09 | 2.44 |
| \(\sigma_r(r=0.01, A_L<1), \times 10^{-3}\) | 1.85 | 1.44 | 1.42 |
| \(\sigma_r(r=0.01, A_L=1), \times 10^{-3}\) | 7.92 | 3.85 | 2.98 |
It is worth noting that this framework has been validated against simulations at the BKP and BK14 noise-levels, and further development is in progress to perform validations with map-level simulations of skies with various degrees of complexity, provided by groups such as Jo/Ben/David or Ghosh/Aumont/Boulanger.
| \(f_{sky}=0.01\) | \(f_{sky}=0.05\) | \(f_{sky}=0.10\) | |
|---|---|---|---|
| \(\sigma_r(r=0, A_L<1), \times 10^{-3}\) | 0.23 | 0.31 | 0.36 |
| \(\sigma_r(r=0, A_L=1), \times 10^{-3}\) | 3.59 | 1.70 | 1.27 |
| \(\sigma_r(r=0.01, A_L<1), \times 10^{-3}\) | 1.30 | 0.87 | 0.77 |
| \(\sigma_r(r=0.01, A_L=1), \times 10^{-3}\) | 5.02 | 2.33 | 1.72 |
| \(f_{sky}=0.01\) | \(f_{sky}=0.05\) | \(f_{sky}=0.10\) | |
|---|---|---|---|
| \(\sigma_r(r=0, A_L<1), \times 10^{-3}\) | 0.22 | 0.31 | 0.36 |
| \(\sigma_r(r=0, A_L=1), \times 10^{-3}\) | 3.44 | 1.65 | 1.23 |
{kind=link}
{kind=link}
{kind=link}