{kind=link}
{kind=link}
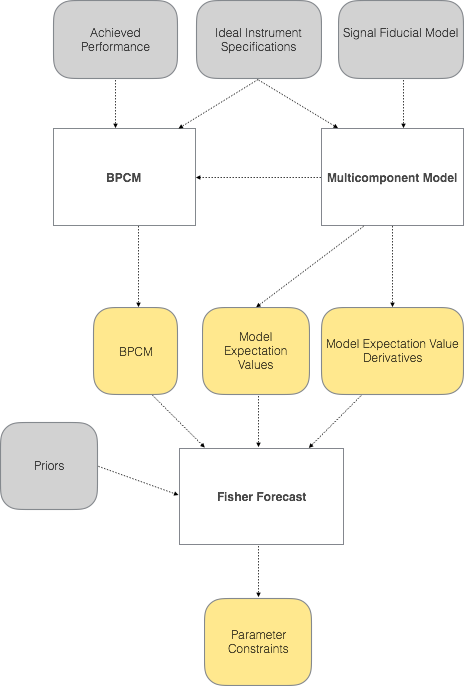
Figure 1:
This is a schematic representation of our Fisher Machinery. Grey
ovals represent User Inputs, White boxes represent Code Modules,
and Yellow ovals represent Code Outputs.
This posting describes the development of a Fisher forecasting framework (developed by Victor Buza, Colin Bischoff, and John Kovac), specifically targeted towards optimizing tensor-to-scalar parameter constraints in the presence of Galactic foregrounds and gravitational lensing of the CMB. I first describe the methodology and then present an example forecast for CMB-S4.
Figure 1 is a schematic representation of the framework, indentifying the user inputs, code modules, and outputs of said modules. This code overlaps significantly with the code used for the BICEP/Keck likelihood analysis and our belief in the projections is grounded in that connection to achieved performance / published results. In particular, we emphasize the importance of using map-level signal and noise sims (of the BICEP2/Keck dataset) as a starting point. We know that these sims are a good description of our maps because we pass jackknife tests derived from them.
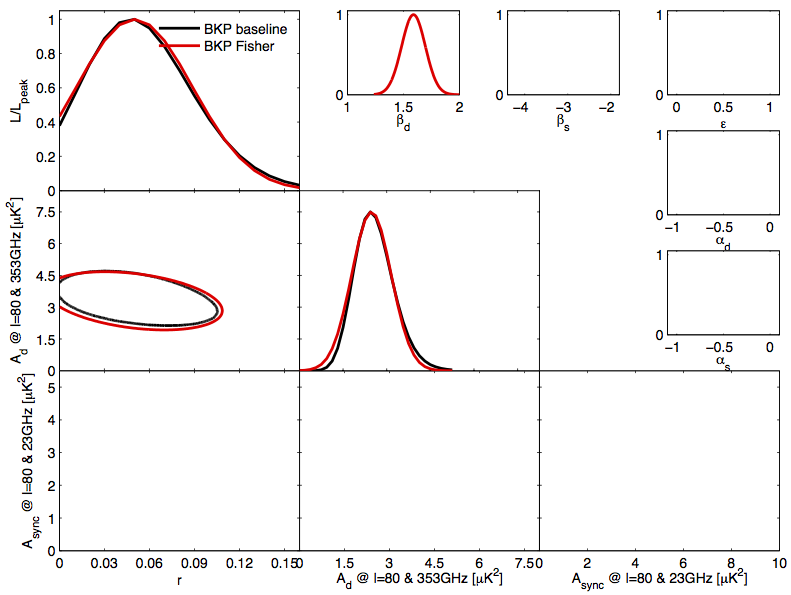
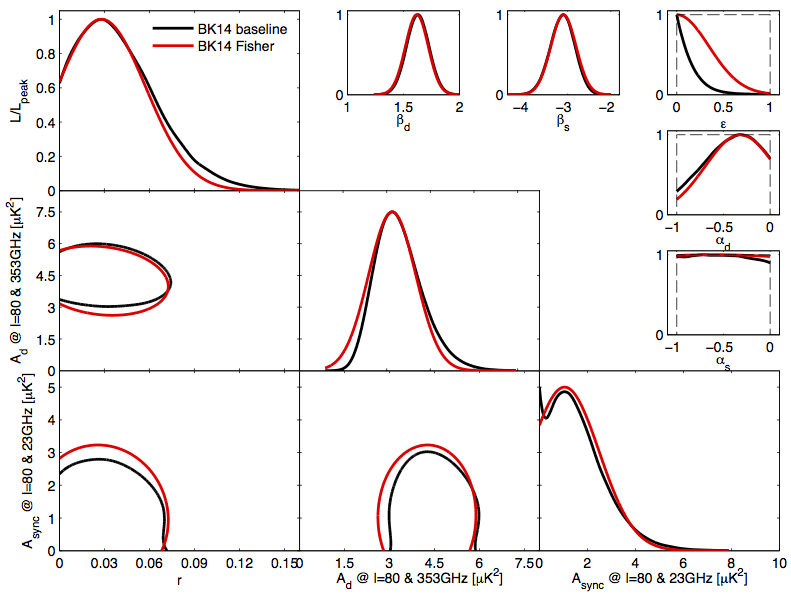
Our confidence in these projections is further enhanced by their ability to recover achieved parameter constrains quoted in the BKP and BK14 papers. BK14 quotes an achieved \(\sigma_r=0.024\) by performing an 8-dimensional ML search (with priors) on a set of 499 Dust + \(\Lambda\)CDM sims, and deriving the standard deviation of the recovered \(r_{ML}\). Though BKP did not do a similar exercise, were it to do that, it would have quoted \(\sigma_r=0.032\). Our Fisher forecasts for these particular scenarios recover \(\sigma_r=0.033\) and \(\sigma_r = 0.024\), which are within sample variance (from the finite number of sims) from the real results. For the particular data draws of BKP and BK14, we can even compare the marginalized posteriors to the Fisher Contours, though this is a weaker comparsion. Firstly, we know the Fisher Contours will be Gaussian, while the real contours will likely not (BKP and BK14 use the H-L likelihood approximation), and secondly, we know that each particular data realization will yield differently shaped contours, so an ideal match of Fisher Contours to any particular realization should not be expected. Nonetheless, the contours are still quite faithfully recovered: BKP vs Fisher, BK14 vs Fisher.
The twelve parameters defining our model are:
Signal Scaling:
The output model expectation values can also be useful in the formation of
our bandpower covariance matrix. For the multicomponent analysis, we have been using lensed-LCDM + \(A_{dust}\)=3.75 (signal + noise) sims to construct the bandpower covariance matrix components. But, because we have the individual signal-only, noise-only, and signal x noise terms, we can record all the bpcm components:
and then rescale and combine them to create a bandpower covariance matrix for a new desired multicomponent model. Here, \(S\) are signal sims, \(N\) are noise sims, and the indices \(i,j,k,l\) run over fields in the analysis, i.e. all combinations of a map type (\(T, E, B\)) and an experiment (BK, P353, etc.). For many combinations of indices, we set certain covariance terms to be identically zero—\(\mathit{Cov}(N_{BK} \times N_{BK}, N_{P353} \times N_{P353})\), for example. It is worth noting that having all of these terms allow us to have different number of degrees of freedom per bandpower for noise than for signal, a complication that is often ignored in other analyses by setting the noise and signal degrees of freedom to be identical.
While calculating the covariances from the signal and noise sims, we record the average signal bandpowers from the sims. For a new signal model, we can calculate the new bandpower expectation values, and rescale the signal components in the bandpower covariance matrix by the appropriate power of the ratio of the recorded average signal bandpowers, and the newly calcualted expectation values.
The ability to get a BPCM for any model is a great one to have, because it means you don't have to run sims for any and all concievable scenarios, all you need is one set of sims. I should emphasize that we only apply this step once in our process; we do not rescale our BPCM at every step of the way.
Noise Scaling:
In addition to scaling from one signal model to the other, recording
all of the covariance terms allows us to rescale the noise parts as well.
Given a dataset for which we have sims, the noise scaling can go one of two
ways: the first allows one to take a frequency present in the dataset and scale down the noise in the BPCM by the desired amount; the second one allows one to add an additional frequency by taking an existing one, scaling down the noise by the desired amount, and then expanding the BPCM and filling it in with the appropriate variance and covariance terms between this new band, and all of the old ones. These two tools allow us to set up a new data structure to explore any combination of frequency bands, with any sensitivity in each band.
We would like to base our noise scaling factors on achieved sensitivities rather than ideal performances. To that end, we use the achieved survey weights (of BICEP/Keck: {95, 150, 220}) to obtain projected weights for any of the S4 channels.
We can write the survey weight as follows: \[w_{achieved} = \frac{t_{obs}}{\alpha_{\frac{ideal}{achieved}} NET^2_{ideal}}\] where \(\frac{t_{obs}}{\alpha_{\frac{ideal}{achieved}}}\) encapsulates the less-than-ideal observing time, receiver perfomance, cuts, etc. It is the factor that takes us from the ideal scenario to reality. Then, to obtain the survey weight at a new frequency, simply calculate: \[w_{\nu_2,achieved} = w_{\nu_1,achieved} \frac{NET^2_{\nu_1, ideal}}{NET^2_{\nu_2,ideal}}\] The implicit assumption that is made here is that the reality factor for this new frequency is exactly the same as the one from which we are scaling. To not abuse this assumption, the survey weight scaling is always done from the closest frequency that we have an achieved survey weight for, as that is the perfomance that should guide us.
Now, to get \(N_l\)'s at a new frequency by scaling the \(N_l\) from an existing frequency, in addition to scaling them by the ratio of the survey weights, I must note that in our sim pipeline, in applying suppression factors, both the signal and the noise parts of the sims are scaled by the beam of the respective frequency they are calculated for. Therefore, to obtain \(N_l\)'s for one channel by scaling the achieved \(N_l\)'s of another channel, we have to reapply the beam of the second, and scale back by the beam of the first. Under the assumption of Gaussian beams, we can write the full scaling as: \[N_{l,\nu_2} = N_{l,\nu_1} \frac{w_{\nu_1,achieved}}{w_{\nu_2,achieved}} \frac{B^2_{l,\nu_2}}{B^2_{l,\nu_1}}\] where \(B^2_{l} = \exp(-\frac{l(l+1)\theta^2}{8log(2)})\), and \(\theta\) is the FWHM (in radians) of the Gaussian beam. With the \(N_l\)'s scalings on hand, we can perform the above mentioned BPCM operations to arrive at a BPCM that encompasses the intricacies of reality.
Below, I present an application of this framework to an example motivated by previous BICEP/Keck experience.
In this section, I focus on the 1% BICEP/Keck patch, and search for the optimal path for a number of fixed levels of delensing. In addition, I also fold in delensing as an extra band in the optimization, thus allowing the algorithm to decide at each step if the effort is better spent towards foreground separation, or towards reducing the lensing residual. I optimize for two possible levels of tensors: \(r=0\) and \(r=0.01\), and plot the resulting paths, individual map depths in \(\mu K\)-arcmin, the effective lensing residuals (after delensing), the amount of effort spent delensing, \(\sigma_r\)'s, and logarithmic derivatives of \(\sigma_r\). In addition to the various delensing cases, I also consider a Raw Sensitivity case (conditional on zero foregrounds).
Things to note:
(Top, Left) Optimal path indicating the total number of det-yrs, and the
individual distribution of det-yrs at each point.
(Top, Right) Individual map depths for every channel, in \(\mu K\)-arcmin. Calculated from the accumulated weights in each channel on the BICEP2 patch.
(Middle, Left) Ratio of the total effort that is spent on delensing, as
a function of total effort.
(Middle, Right) Effective \(A_L\) as a function of total effort.
(Bottom, Left) Resulting \(\sigma(r)\) constraints for each level of
delensing, as well as from a limiting (conditional on no foregrounds)
raw-sensitivity case.
(Bottom, Right) The logarithmic derivative of \(\sigma(r)\) with
respect to det-yrs, indicating the different regimes of gain.
Our Fisher formalism also includes an \(f_{sky}\) knob. The effects of \(f_{sky}\) are implemented in two steps:
Things to note:
There are a number of effects that penalize large \(f_{sky}\) that are not included in this analysis:
The correlation coefficient for a particular cross spectrum is given by the ratio of the cross-spectrum expectation values to the geometric mean of the auto-spectra (if there is a non-zero decorrelation effect, the cross will register less power than the geometric mean of the autos, R<1). Therefore, the decorrelation coefficient is given by (1-correlation): \[\tilde{R}(217,353) = 1-\frac{< 217\times 353>}{\sqrt{<217\times 217><353 \times 353>}}\] This is a quantity that is less than or equal to one, dependend on the two frequencies involved in the cross, and perhaps different for different scales. We can try to model this more generally by assuming that it has a well-behaved \(l\) and \(\nu\) dependence, reflecting the different degrees of correlation one would get at various scales for different cross spectra: \[R(\nu_1,\nu_2,l) = 1 - g(\nu_1,\nu_2) f(l)\] where \(g(\nu_1,\nu_2)\) and \(f(l)\) can take different function forms. The four fairly natural scale dependencies I have explored are: \(f(l)=al^0\), \(f(l)=al^1\), \(f(l)=alog(l)\), and \(f(l)=al^2\), where \(a\) is a normalization coefficient. I am not motivating these physically, but I will argue that they span a generous range of possible scale dependencies.
Now, for the frequency scaling, John and I came up with a more well-motivated behaviour, and it stems from one of the ways through which decorrelation could be generated. The premise is simple: given a dust map at a pivot frequency, if there is a physical phenomenon that introduces a variation(\(\Delta \beta\)) of the dust frequency spectral index map \(\beta\), when extrapolating to other frequencies, the variation we've just introduced will change the dust SED and create decorrelation effects at various frequencies. We built this toy model so that we could study the resulting frequency dependence, and we've come up with the empirical form (where \(g'\) is a normalization factor): \[g(\nu_1,\nu_2)=g'*log\left(\frac{\nu_1}{\nu_2}\right)^2\]
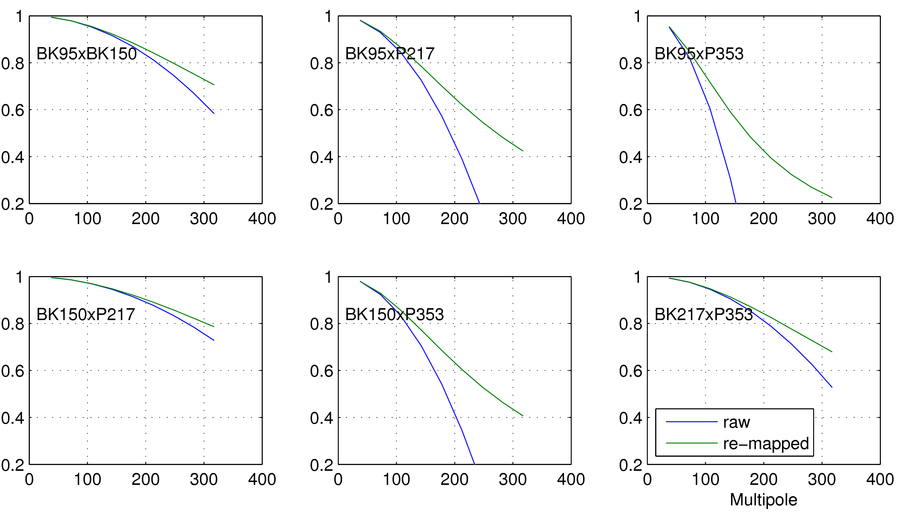
For the analysis below I define my normalization factor \(a*g'\) such that \(g(217,353)=1\) and \(f(l=80)=a\), making \(R(217,353,80)=1-a\). The reason for this normalization definition is mostly the historic over-representation of \(R(217,353,l)\) in conversations about decorrelation. In my studies, the form of \(f(l)\) (out of the ones listed above) that yields the largest decorrelation effects is unsurprisingly \(f(l)=a l^2\); therefore, as an example of an extreme case, I pick this \(f(l)\) shape, and choose my normalization coefficient to be \(a=0.03\), which PIPXXX, Appendix E says is \(1\sigma\) away from the mean decorrelation over the studied LR regions. For this particular \(a\) and \(f(l)\) choice, my correlation remapping looks (for a few of the more important cross spectra for a BK14-like analysis), like this. Notice that these are generally large values of decorrelation.
First, I would like to show an example by demonstrating the decorrelation effects for a BK14 evaluation: BK14 Fisher Ellipses with (black) and without (red) Decorrelation. You can notice the degeneracies of the decorrelation parameter with the dust parameters, as well as \(r\). In addition, this also makes it easy to observe the effects of the decorrelation on the constraints of these parameters; in particular, we see that it introduces more degeneracy in the \(r\) vs \(A_d\) plane, and weakens the \(r\) and \(A_d\) constraints. It's worth noting that even though the decorrelation parameter was left unbounded in the Fisher calculation, it's resulting ellipse is reasonably constrained.
Next, I perform the same optimization as done in Figure 2, except now with the ability to turn this decorrelation parameter on. I only perform the optimization with an adaptive delensing treatment (and do not do it for the fixed delensing levels), meaning that the delensing is introduced as an extra band in the problem.
(Top, Left) Optimal path indicating the total number of rx-yrs, and the
individual distribution of rx-yrs at each point.
(Top, Right) Individual map depths for every channel, in \(\mu K\)-arcmin. Calculated from the accumulated weights in each channel on the BICEP2 patch.
(Middle, Left) Ratio of the total effort that is spent on delensing, as
a function of total effort.
(Middle, Right) Effective \(A_L\) as a function of total effort.
(Bottom, Left) Resulting \(\sigma(r)\) constraints for each level of
delensing, as well as from a limiting (conditional on no foregrounds)
raw-sensitivity case.
(Bottom, Right) The logarithmic derivative of \(\sigma(r)\) with
respect to rx-yrs, indicating the different regimes of gain.
Next, I re-do the \(f_{sky}\) optimization, similarly to Figure 3, with the ability to turn decorrelation ON and OFF. As expected, the \(\sigma_r\) constraints degrade, and a portion of the effort that used to be spend on delensing got reallocated to foreground separation. Additionally, one can see the slope (with \(f_{sky}\)) becoming slightly shallower, though in principle, the optimal solution remains vastly the same.
{kind=link}
{kind=link}
{kind=link}