Left: \(N_{l}\)'s for the Degree Scale effort that
went into Data Challenges 2.0 and 3.0, amounting to ~575k actual
det-yrs on \(f_{sky}=0.03\), as recorded here
Middle: \(N_{l}\)'s for the Arminute Scale effort that
went into the optimization for DC2.0 and DC3.0, amounting
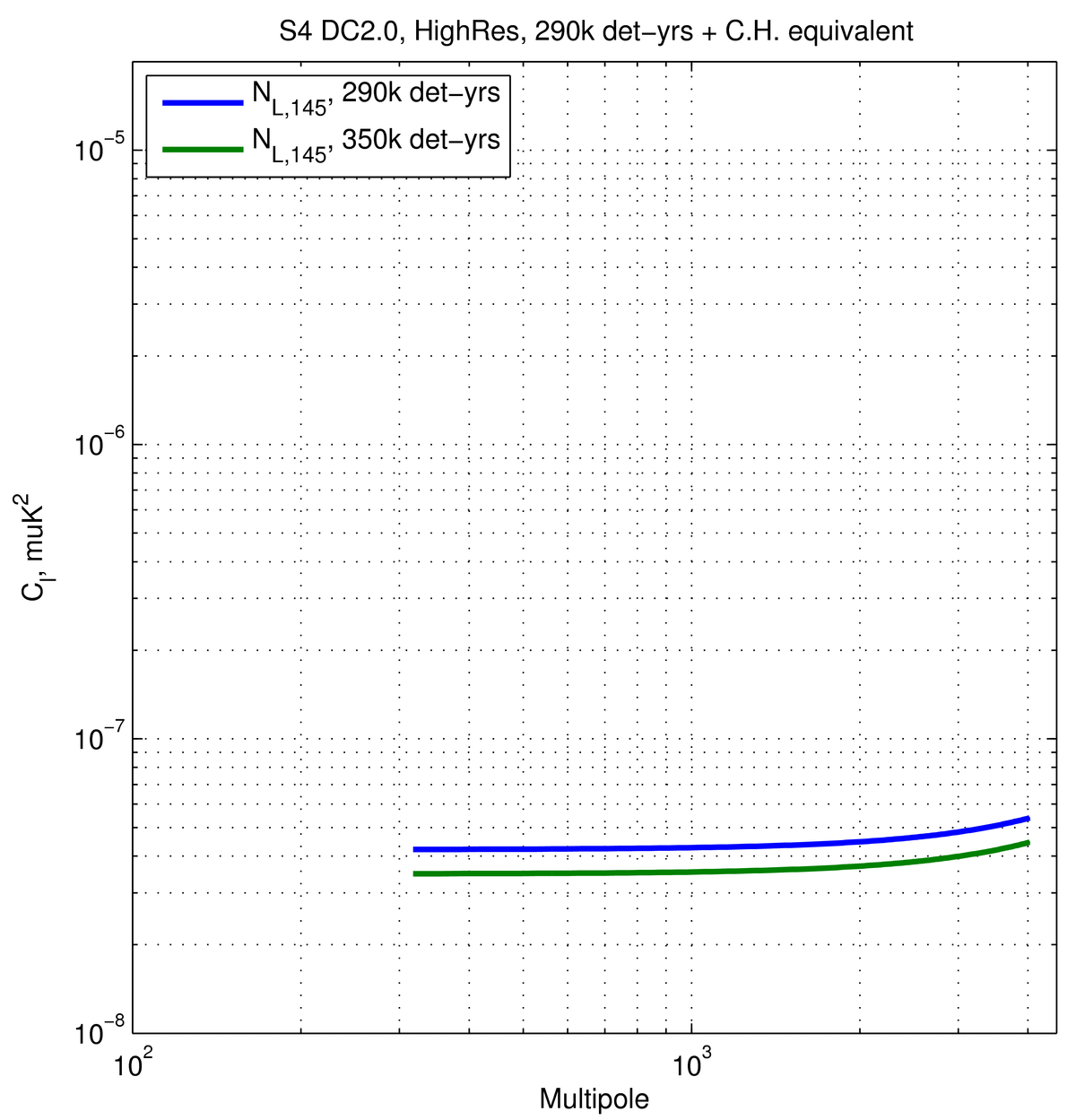
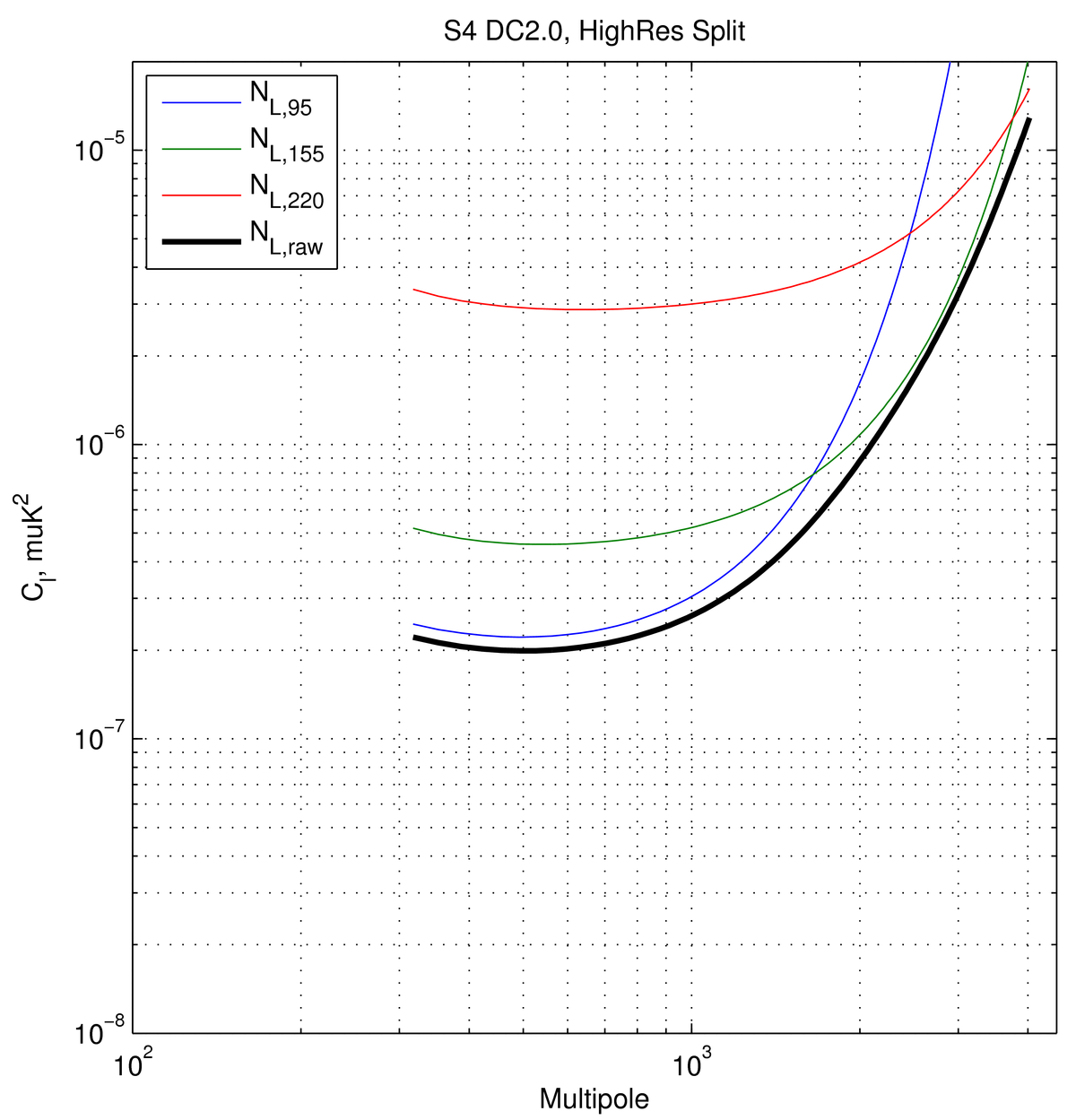
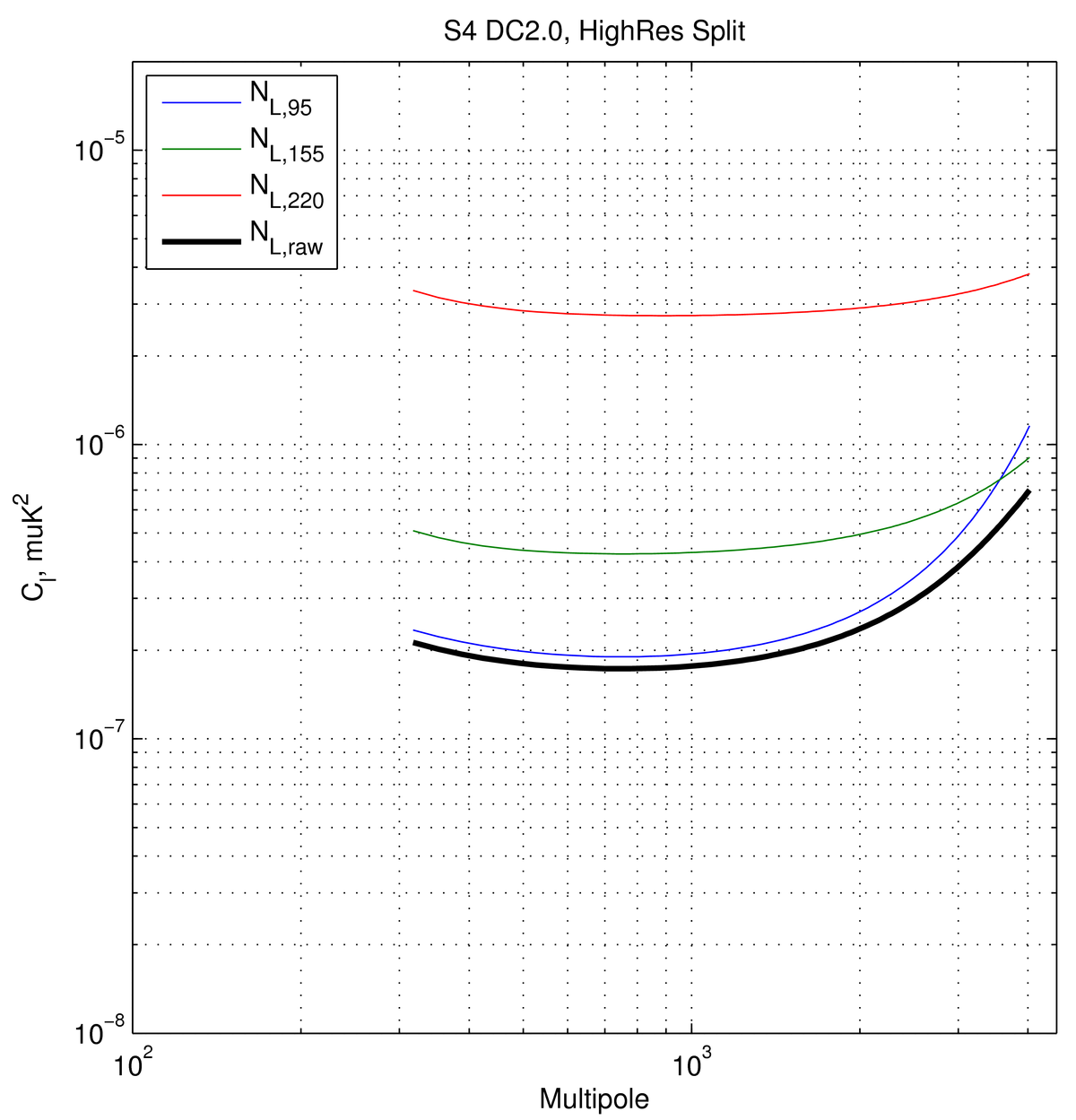
to ~290k actual det-yrs (at 145 GHz) on \(f_{sky}=0.03\), as recorded here. For the data challenges, this effort was ultimately split into three
bands -- see next section for details. The high-res
details are recorded above.
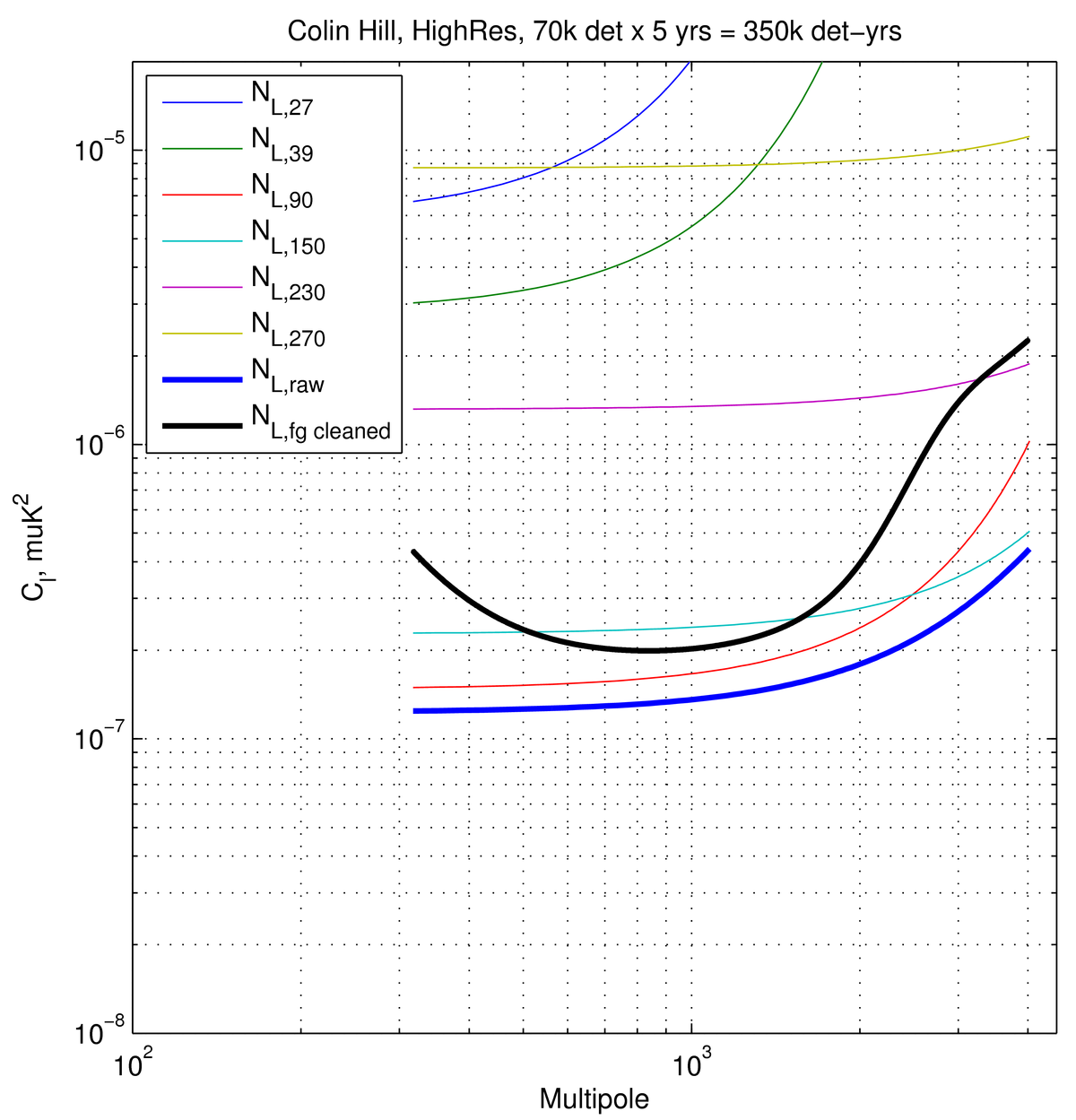
In addition, I also add a 350k det-yr case for comparison with the plot
in the last section.
Right: \(N_{l}\)'s for the Arcminute Scale effort that went into
the the optimization for DC2.0 and DC3.0, taking into account filtering
and survey non-uniformity (described above). These curves are effectively
directly scaled-down versions of the yellow or black curves in the
left-most panel (after accounting for beam factors and the presence of
1/f noise in the LowRes panel).
Note: One can note the difference between the "HighRes" and "HighRes (+terms)" noise curves, and that the difference results, for this particular case, in a 4% increase in residual lensing power.
| HighRes | HighRes (+terms) | |
|---|---|---|
| 290k det-yrs | \(A_L=0.09\) | \(A_L=0.13\) |
| 350k det-yrs | \(A_L=0.08\) | \(A_L=0.12\) |


{kind=link}
{kind=link}