B. Racine
Now includes models 7, 8 and 9 (only 300 simulations).
Edited on October 2nd: added a no prior case and reporting now the log-like value for each model.
Tables now show case with no bias. Older tables are in the original posting.
This posting summarizes results from analysis of CMB-S4 Data Challenge 04
using a BICEP/Keck-style parametrized foreground model.
There are a few additional changes compared to the DC02 analysis:
• we fixed the lensing spectrum to the input one. In the previous posting it uses a lensing spectrum that differs from the input,
• we zero out the theory spectrum below ell=30, since that's what was done in the sims.
The current posting is an update over this previous DC04 posting, where we introduced a cut to remove outliers in the likelihood values due to flawed simulations.
We added three sky models, described below.
As in the previous posting, we now use power spectra that have been re-generated to fix a bug, as shown in this posting.
In section 1, we show the main results in the form of figures and histograms including foreground parameters.
In section 2, we report tables of r constraints for the different sky models, for different lensing residuals, with and without decorrelation in the ML search.
To-do: In the next run, we will probably release the priors on the foreground parameters.
Note about the model:
In this analysis, for each realization, we find the set of model parameters that maximizes the likelihood multiplied by priors on the dust and sync spectral index parameters (\(\beta_d\) and \(\beta_s\)).
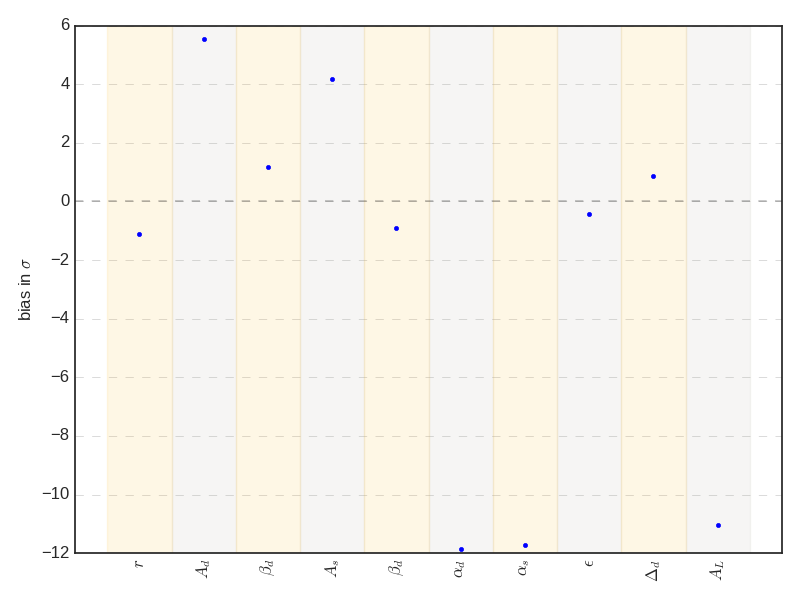
These priors are based on Planck data, so they are quite weak in comparison with CMB-S4 sensitivity. However, in principle foreground models may violate them potentially leading to biases (e.g. model 03 where the preferred value of \(\beta_d\) is outside the prior range - see below, Figure 2).
The model includes the following parameters:
We also now have a case without these Gaussian priors, where we removed the priors on \(\beta_s\) and \(\beta_d\). We also opened a 5% Gaussian prior on the lensing parameter \(A_L\), which takes into acount the sample variance on the lensing spectrum.
For the decorrelation model, we assume that the cross-spectrum of dust between frequencies \(\nu_1\) and \(\nu_2\) is reduced by factor \(\exp\{log(\Delta_d) \times [\log^2(\nu_1 / \nu_2) / \log^2(217 / 353)] \times f(\ell)\}\). For the \(\ell\) dependence we fix the scaling to take a linear form (pivot scale is \(\ell\)=80).
Note about the simulations: (see section 2 for more detail.)
In Figure 1, we summarize the r results, as well as the L=-log(Likelihood) values.
Some of these models produce strong biases, especially model 8, which still has a very significant bias even when we take into account decorrelation in the model. See section 2 for discussions. It seems like using L=-log(Likelihood), we could detect that this model is a bad fit.
This doesn't mean that any model would be picked up by such a test. One could cook up a model that yields a strong bias AND a good fit.
Note that for model 4, \(\beta_d\) is in slight tension with the imposed prior: Gaussian centered at 1.6 with width 0.11. Similarly for \(\beta_s\) in model 6, (compared to the Gaussian centered at -3.1 with width 0.3). Model 8 also seem to prefer a higher value of \(\beta_d\). We can now have a look at the case without prior.
It seems like there is a non negligible bias on the recovered \(A_L\). In the simple Gaussian case, it is half a sigma off, which we detect at more than 10 sigma with the 500 sims (see this plot for the linear decorrelation case, \(A_L\)=0.1, r=0 case), at the same level as what we saw for the \(\alpha\)'s. For model 4, the recovered value is way off.
The mean values and standard deviations of \(r\) for simulations with simple Gaussian foregrounds are summarized in Table 00. With a 10% lensing residual, we don't quite achieve \(\sigma(r) = 5 \times 10^{-3}\) for sims with \(r = 0\).
Turning on dust decorrelation in the model doesn't cause any bias in \(r\) and the recovered \(\Delta_d\) values are centered around 1 (i.e. analysis recovers zero decorrelation). Adding this parameter does increase \(\sigma(r)\) somewhat.
| Decorrelation model | \(A_L\) = 1 | \(A_L\) = 0.3 | \(A_L\) = 0.1 | \(A_L\) = 0.03 |
|---|---|---|---|---|
| Input \(r\) = 0 | ||||
| none | -0.148±2.571 | -0.065±0.925 | -0.039±0.447 | -0.026±0.276 |
| linear | -0.173±2.617 | -0.070±1.018 | -0.029±0.568 | -0.010±0.405 |
| Input \(r\) = 0.003 | ||||
| none | 2.795±2.673 | 2.894±1.099 | 2.937±0.624 | 2.971±0.446 |
| linear | 2.822±2.854 | 2.923±1.299 | 2.976±0.810 | 3.010±0.610 |
When comparing these results to the old posting, we get an improvement on \(\sigma(r)\) due to the outlier rejection. We report these decrease in % in Table 00bis.
| r | \(A_d\) | \(\beta_d\) | \(A_s\) | \(\beta_s\) | \(\alpha_d\) | \(\alpha_s\) | \(\epsilon\) | \(\Delta_d\) |
| 0/0.003 | 4.25 \(\mu K^2\) | 1.6 | 3.8 \(\mu K^2\) | -3.1 | -0.4 | -0.6 | 0 | 0 |
As has been previously noted, dust power is much higher in this model (\(A_d \sim 12.5 \mu K^2\)) than for the Gaussian foreground sims (\(A_d = 4.25 \mu K^2\)). The PySM d1 dust model does feature a spatially varying spectral index, but we don't find any detectable decorrelation in this analysis. The PySM s1 synchrotron model yields \(A_s \sim 0.5 \mu K^2\) and there is \(\sim 6\)% correlation between dust and sync.
Note here that the value of \(\sigma(r)\) doesn't change much compared to the 04.00 case despite having a higher dust level. This is probably due to the fact that we only have one realization of the foreground sky (see note in the introduction), thus no impact from cosmic variance.
| Decorrelation model | \(A_L\) = 1 | \(A_L\) = 0.3 | \(A_L\) = 0.1 | \(A_L\) = 0.03 |
|---|---|---|---|---|
| Input \(r\) = 0 | ||||
| none | 0.913±2.625 | 0.816±0.961 | 0.663±0.477 | 0.538±0.305 |
| linear | 0.738±2.726 | 0.645±1.111 | 0.489±0.638 | 0.379±0.446 |
| Input \(r\) = 0.003 | ||||
| none | 3.868±2.697 | 3.759±1.129 | 3.644±0.663 | 3.573±0.486 |
| linear | 3.724±2.842 | 3.629±1.314 | 3.522±0.846 | 3.458±0.655 |
The d4 version of PySM dust adds a second dust component (with different blackbody temperature and emissivity power law) based on Meisner & Finkbeiner (2014). Not sure what type of \(\beta_d\) spatial variations are included in this model, but Colin thinks it is more or less the same as for d1. The s3 synchrotron model adds curvature to the synchrotron spectral index: \(\beta_s \rightarrow \beta_s + C \ln (\nu / \nu_C)\). The a2 AME model uses a 2% polarization fraction for AME, which seems very high, but there is no attempt to model AME in this analysis.
Results for this model show that \(A_d\) is even larger (\(\sim 32.5 \mu K^2\)) than for the d1 dust model. The mean value of \(\beta_d\) decreases from 1.59 (for PySM d1 model) to 1.55, which is probably a sign of the two component dust. The mean value of \(\beta_s\) decreases from -3.05 (for PySM s1 model) to -3.13, which is probably due to synchrotron spectral curvature (and perhaps polarized AME?). Dust–sync correlation is higher, at \(\sim 10\)%, which could be from polarized AME.
Note here that the value of \(\sigma(r)\) doesn't change much compared to the 04.00 case despite having a much higher dust level. This is probably due to the fact that we only have one realization of the foreground sky (see note in the introduction), thus no impact from cosmic variance.
| Decorrelation model | \(A_L\) = 1 | \(A_L\) = 0.3 | \(A_L\) = 0.1 | \(A_L\) = 0.03 |
|---|---|---|---|---|
| Input \(r\) = 0 | ||||
| none | 0.367±2.649 | 0.372±0.983 | 0.340±0.484 | 0.316±0.299 |
| linear | 0.035±2.790 | 0.110±1.160 | 0.153±0.654 | 0.174±0.442 |
| Input \(r\) = 0.003 | ||||
| none | 3.311±2.608 | 3.346±1.096 | 3.332±0.652 | 3.334±0.480 |
| linear | 3.019±2.695 | 3.114±1.229 | 3.163±0.789 | 3.192±0.609 |
The next PySM version uses the Hensley/Draine dust model, which has additional complexity in the dust SED (perhaps described in arXiv:1709.07897?). The level of dust power is similar to sky model 01 (PySM d1 model), but we find that the emissivity power law is even flatter than the last case, with \(\beta_d \sim 1.44\).
The recovered means seem quite wacky, and \(A_L\) dependent.
Note here that the value of \(\sigma(r)\) doesn't change much compared to the 04.00 case despite having a higher dust level. This is probably due to the fact that we only have one realization of the foreground sky (see note in the introduction), thus no impact from cosmic variance.
| Decorrelation model | \(A_L\) = 1 | \(A_L\) = 0.3 | \(A_L\) = 0.1 | \(A_L\) = 0.03 |
|---|---|---|---|---|
| Input \(r\) = 0 | ||||
| none | 0.611±2.605 | 0.645±0.953 | 0.577±0.482 | 0.501±0.314 |
| linear | -0.294±2.746 | -0.102±1.147 | 0.011±0.673 | 0.083±0.476 |
| Input \(r\) = 0.003 | ||||
| none | 3.879±2.700 | 3.737±1.131 | 3.622±0.669 | 3.551±0.497 |
| linear | 2.995±2.802 | 2.994±1.317 | 3.050±0.872 | 3.115±0.681 |
The Ghosh dust model (described here) is based on GASS HI data with a model for the Galactic magnetic field. For these sims, it is combined with the PySM a2, f1, and s3 components (same as the two previous models).
The analysis of this model yields smaller still values of \(\beta_d \sim 1.3-1.4\). Dust-sync correlation is still present, but smaller (2–3%), which is probably due to the fact that the Ghosh dust sims don't know anything about the PySM synchrotron or AME components. The fact that they are correlated at all probably happens because both models are based on data at larger scales.
Dust decorrelation is small in absolute terms, but detected at high significance. Using a model without dust decorrelation leads to a large positive bias on \(r\) in the range \(4-5 \times 10^{-3}\). Dust decorrelation with linear \(\ell\) scaling produces the smallest biases, but still quite large compared to other sky models.
| Decorrelation model | \(A_L\) = 1 | \(A_L\) = 0.3 | \(A_L\) = 0.1 | \(A_L\) = 0.03 |
|---|---|---|---|---|
| Input \(r\) = 0 | ||||
| none | 1.657±2.751 | 2.137±1.185 | 2.880±0.732 | 4.452±0.613 |
| linear | -1.408±2.845 | -0.898±1.306 | -0.861±0.830 | -1.049±0.633 |
| Input \(r\) = 0.003 | ||||
| none | 5.077±3.060 | 5.493±1.416 | 6.412±0.945 | 8.429±0.856 |
| linear | 1.789±3.091 | 2.216±1.520 | 2.270±1.045 | 2.079±0.855 |
This model has extremely large dust decorrelation (15% between 217 and 353 GHz at \(\ell\) = 80) and it exactly follows the assumed functional form of decorrelation with linear \(\ell\) scaling, so we can still draw some useful conclusions.
When we choose decorrelation with linear \(\ell\) scaling to match the sims, then we find no bias on \(r\) and recover \(\Delta_d\) = 0.85.
An important point to note from this model is that, even for the unbiased case where the decorrelation is correctly modeled in both \(\nu\) and \(\ell\), we find \(\sigma(r) \sim 1.4\), much larger than the target sensitivity of CMB-S4. This shows that, for extreme levels of foreground decorrelation, we lose the ability to clean foregrounds from the maps because the foreground modes are significantly independent between the various CMB-S4 frequencies. Regardless of whether you are doing map-based cleaning or fitting the power spectra as we do here, the only way to improve sensitivity would be use more observing bands that are more closely spaced. It also makes the point that our Fisher forecasts should assume some non-zero level of decorrelation. Adding decorrelation as a free parameter to a forecast that assumes \(\Delta_d = 1\) only captures part of the statistical penalty.
| Decorrelation model | \(A_L\) = 1 | \(A_L\) = 0.3 | \(A_L\) = 0.1 | \(A_L\) = 0.03 |
|---|---|---|---|---|
| Input \(r\) = 0 | ||||
| none | 34.859±6.669 | 28.411±4.401 | 28.302±2.773 | 38.323±3.058 |
| linear | -0.120±3.526 | -0.074±1.956 | -0.026±1.499 | -0.001±1.308 |
| Input \(r\) = 0.003 | ||||
| none | 38.368±7.188 | 32.247±4.576 | 31.949±2.977 | 42.605±3.215 |
| linear | 2.710±3.709 | 2.897±2.136 | 3.020±1.667 | 3.075±1.508 |
Our understanding is that this model uses MHD simulations to consistently model polarized dust and synchrotron in the Galactic magnetic field. This makes it quite interesting that this analysis finds negative dust-sync correlation with \(\epsilon \sim -0.36\). The dust power is similar to the Gaussian sims, and \(\beta_d\) matches the Planck value of 1.59. This analysis finds a synchrotron SED power law that is much flatter than usual, \(\beta_s \sim -2.6\), which is inconsistent with the prior at about \(1.5 \sigma\).
This model does not show any significant dust decorrelation. In general, the results for this model look nearly as good as the simple Gaussian foregrounds (sky model 00).
| Decorrelation model | \(A_L\) = 1 | \(A_L\) = 0.3 | \(A_L\) = 0.1 | \(A_L\) = 0.03 |
|---|---|---|---|---|
| Input \(r\) = 0 | ||||
| none | -0.089±2.525 | -0.003±0.961 | 0.013±0.501 | 0.028±0.324 |
| linear | 0.063±2.593 | 0.145±1.093 | 0.146±0.657 | 0.130±0.476 |
| Input \(r\) = 0.003 | ||||
| none | 3.056±2.964 | 3.077±1.246 | 3.074±0.711 | 3.081±0.499 |
| linear | 3.221±3.025 | 3.242±1.364 | 3.228±0.856 | 3.204±0.656 |
This model is described here. It is a modified version of model 00, where the brightness of the dust varies across the sky. It does not include any decorrelation. It was mostly developped to study the effect of mask variations, shown in this separate posting.
| Decorrelation model | \(A_L\) = 1 | \(A_L\) = 0.3 | \(A_L\) = 0.1 | \(A_L\) = 0.03 |
|---|---|---|---|---|
| Input \(r\) = 0 | ||||
| none | -0.255±2.575 | -0.107±0.921 | -0.064±0.435 | -0.045±0.256 |
| linear | -0.315±2.673 | -0.118±1.071 | -0.044±0.599 | -0.016±0.417 |
| Input \(r\) = 0.003 | ||||
| none | 3.073±2.609 | 2.996±1.114 | 2.973±0.659 | 2.971±0.473 |
| linear | 3.188±2.774 | 3.090±1.333 | 3.062±0.886 | 3.048±0.694 |
Model 8 has been developped by Martinez-Solaeche, Karakci, Delabrouille, (see this paper). As described in their abstract: This is a "three-dimensional model of polarised galactic dust emission that takes into account the variation of the dust density, spectral index and temperature along the line of sight, and contains randomly generated small scale polarisation fluctuations. The model is constrained to match observed dust emission on large scales, and match on smaller scales extrapolations of observed intensity and polarisation power spectra.". It is based on a multi-layer model where \(T_d\), \(\beta_d\) and the optical depth \(\tau\) is defined in each layer, constrained by Planck, IRAS, some 3D dust extinction maps. A simple model of the galactic magnetic field is used to generate the large scale polarization. For the small scales, some Gaussian random I, E and B based on Planck observed power spectra are generated in each layers. It is then extrapolated at different frequencies, based on random realizations of \(\beta_d\) and \(T_d\) in the different layers, defining the dust SED.
This model naturally produces dust decorrelation, due to a varying SED on the sky. It is also expected to produce a flattening at low frequency, as is briefly reported in figure 19 of the paper. This might be explaining the large bias we observe on r, reduced but still present at high significance when including a decorrelation parameter.
| Decorrelation model | \(A_L\) = 1 | \(A_L\) = 0.3 | \(A_L\) = 0.1 | \(A_L\) = 0.03 |
|---|---|---|---|---|
| Input \(r\) = 0 | ||||
| none | 6.028±2.838 | 5.126±1.139 | 4.264±0.634 | 3.573±0.432 |
| linear | 4.046±2.934 | 3.226±1.308 | 2.522±0.843 | 2.074±0.659 |
| Input \(r\) = 0.003 | ||||
| none | 8.933±2.770 | 7.949±1.311 | 7.153±0.847 | 6.573±0.639 |
| linear | 7.110±2.876 | 6.234±1.518 | 5.637±1.093 | 5.281±0.897 |
Model 9 has been developped by Vansyngel et al. (see this paper, and this posting). In this model, each layer has the same intensity (constrained by the Planck intensity map), but different magnetic field realizations. It produces Q and U maps by integrating along the LOS over these multiple layers of magnetic fields. This magnetic field, contrary to the previous model, is simulated down to small turbulent scales, which produce more physically motivated non-Gaussian fluctuations in the maps (down to small scales). These maps are then linearly rescaled to match the TE correlation from Planck and E-B assymetry. (Note that in the map we study here, there is no TE correlation, see here ).
This model naturally produces non-Gaussian dust patterns, but the decorrelation is ad-hoc, via some extrapolation at different frequencies using a pixel-dependent modified blackbody emission law. It is much stronger than in, say, model 01, which also have such extrapolation. I think this might be dut to the fact that PySM uses \(\beta_d\) and \(T_d\) maps from \(\texttt{Commander}\), whereas Flavien uses the same recipe as the FFP sims described here, which use the GNILC maps. Flavien made this plot, using only 1% of the pixels of the maps (Note that the reduction of the spread might be due to the resolution of the Commander map, which might have been smoothed?).
Note that in the current results, the bandwidth at 20GHz used in the ML search was the usual one used for other models (5GHz), whereas the simulations have been generated with a width of 6GHz.
| Decorrelation model | \(A_L\) = 1 | \(A_L\) = 0.3 | \(A_L\) = 0.1 | \(A_L\) = 0.03 |
|---|---|---|---|---|
| Input \(r\) = 0 | ||||
| none | 3.502±2.631 | 3.033±1.017 | 2.455±0.549 | 1.951±0.367 |
| linear | 0.367±2.922 | -0.098±1.317 | -0.562±0.810 | -0.828±0.594 |
| Input \(r\) = 0.003 | ||||
| none | 6.458±2.802 | 5.870±1.276 | 5.348±0.784 | 4.944±0.571 |
| linear | 3.693±3.043 | 3.074±1.528 | 2.648±1.026 | 2.402±0.823 |
As can be seen in figure 4 of the last posting, we still have biases even in the case of the Gaussian foreground simulations, mostly for the foreground parameters. In this posting this last has been improved.
Just as for the CDT report, we remove this "algorithmic bias" to focus on the bias produced by the different dust simulations. We also chose to report results using the linear \(\ell\) dependence for the decorrelation model. See caption of Table 10. As we have seen in
For the case with the priors, results can be seen <>table10
For the case with the priors, results can be seen in the former posting.| \(r\) bias \(\times 10^4\) | \(\sigma(r) \times 10^4\) | |||
| Input \(r\) = 0 | ||||
|---|---|---|---|---|
| 04.00 | 0.3 | 5.7 | ||
| 04.01 | 5.2 | 6.4 | ||
| 04.02 | 1.8 | 6.5 | ||
| 04.03 | 0.4 | 6.7 | ||
| 04.04 | -8.3 | 8.3 | ||
| 04.05 | 0.0 | 15.0 | ||
| 04.06 | 1.8 | 6.6 | ||
| 04.07 | -0.2 | 6.0 | ||
| 04.08 | 25.5 | 8.4 | ||
| 04.09 | -5.3 | 8.1 | ||
| Input \(r\) = 0.003 | ||||
| 04.00 | 0.4 | 8.1 | ||
| 04.01 | 5.5 | 8.5 | ||
| 04.02 | 1.9 | 7.9 | ||
| 04.03 | 0.7 | 8.7 | ||
| 04.04 | -7.1 | 10.5 | ||
| 04.05 | 0.4 | 16.7 | ||
| 04.06 | 2.5 | 8.6 | ||
| 04.07 | 0.9 | 8.9 | ||
| 04.08 | 26.6 | 10.9 | ||
| 04.09 | -3.3 | 10.3 | ||
{kind=link}
{kind=link}